





Prendiamo un telescopio con la capacità di osservare a lungo grandi regioni di cielo e raccogliere dati su moltissimi degli oggetti celesti (vicini e lontani) che le illuminano, come farà il nuovo osservatorio Vera Rubin, in Cile. Ciò che uscirà dai suoi occhi e dai suoi strumenti sarà una lista di oggetti celesti, tutti quelli che è riuscito a distinguere, magari con alcuni valori “grezzi” riguardanti la loro luminosità a diverse lunghezze d’onda, e quindi il loro colore, senza però alcuna indicazione sulla loro natura. Per questo una delle prime cose da fare è distinguere fra questi stelle, galassie e altre sorgenti di luce. Come? Con algoritmi e, naturalmente, con la supervisione visiva degli addetti ai lavori. Ma il metodo migliore, secondo uno studio appena pubblicato su The Astrophysical Journal Supplement Series, sarebbe un nuovo algoritmo basato su reti neurali che riescono a combinare diverse tecniche insieme.
Cominciamo con un paio di precisazioni. La classificazione degli oggetti di cui parlavamo sopra, nel caso di una ampia survey come quella che sta conducendo il telescopio spaziale Euclid, che condurrà il telescopio Vera Rubin, o che in passato hanno portato a termine il telescopio Cfht alle Hawaii o il progetto Sloan Digital Sky Survey (Sdss) e Kilo-Degree Survey (Kids), divide tutte le sorgenti essenzialmente in tre grandi categorie: stelle, galassie e Agn o quasar (vedi l’immagine qui sotto). Tutte le survey appena citate si basano per lo più su informazioni fotometriche, ovvero ottenute semplicemente dalle immagini e dalle misure della quantità di luce raccolta, per ogni oggetto, in varie lunghezze d’onda, e quasi mai sugli spettri dei singoli oggetti. Sebbene le osservazioni spettroscopiche offrano classificazioni ad alta precisione, richiedono molto più tempo e risorse, per cui solitamente, se effettuate, non riescono a coprire tutti gli oggetti osservati. Al contrario, l’imaging fotometrico (e cioè la raccolta della luce in diverse bande) è più efficiente e sensibile anche agli oggetti più deboli. Per questo motivo, la classificazione degli oggetti celesti osservati è basata esclusivamente sulle caratteristiche morfologiche o sulla distribuzione spettrale dell’energia (Sed), intrinsecamente meno precise e passibili di ambiguità. Ad esempio, quasar e stelle molto lontane appaiono entrambi come sorgenti puntiformi nelle immagini, il che li rende difficili da distinguere.
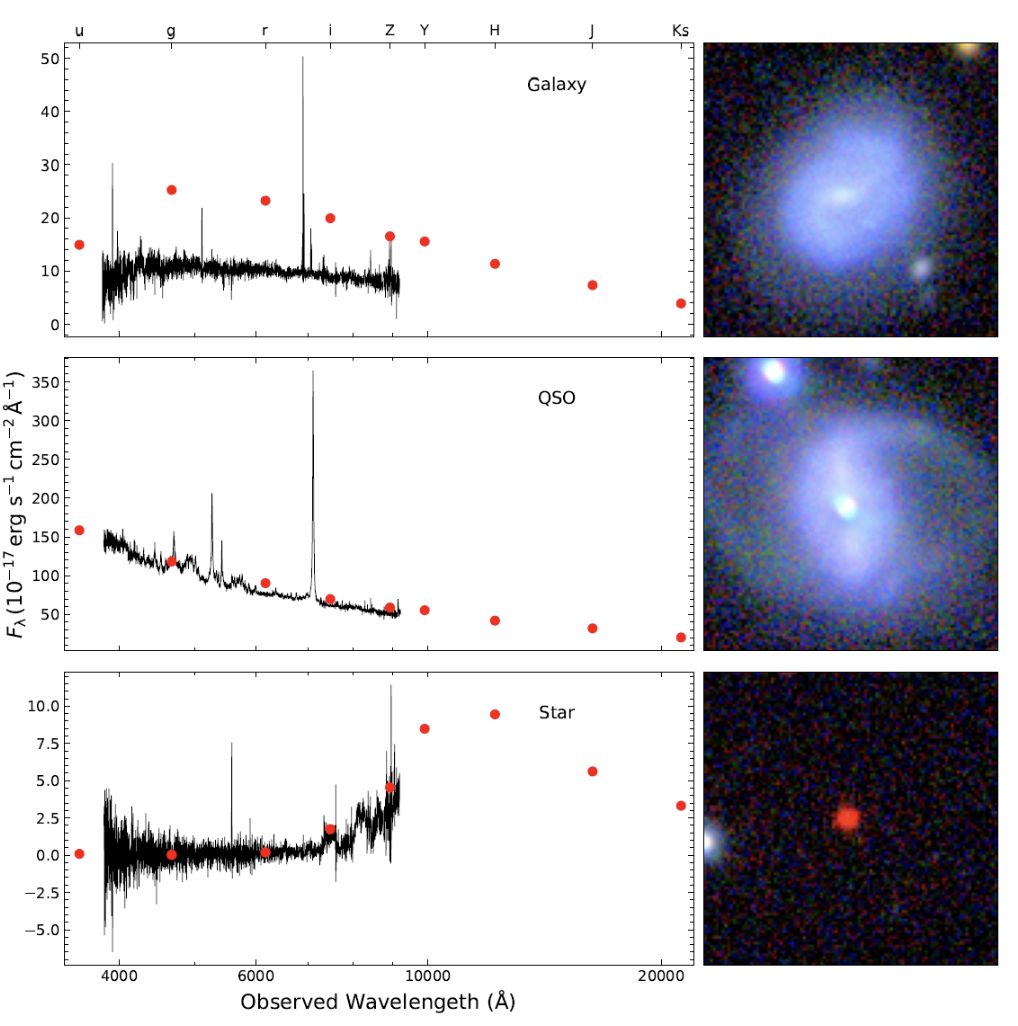
Un confronto fra le Sed (i punti rossi), le caratteristiche spettroscopiche (in nero) e le morfologie spaziali (le immagini sulla destra) di diversi tipi di oggetti celesti. Dall’alto verso il basso, gli esempi mostrati corrispondono a una galassia, un quasar e una stella. I dati spettroscopici provengono dalla Sdss, mentre le Sed e i dati delle immagini provengono da Kids. Crediti: Feng Hai-Cheng et al. (2025)
Per questo gli autori del nuovo studio hanno pensato di creare un modello di rete neurale multimodale in grado di elaborare simultaneamente sia le caratteristiche morfologiche che quelle provenienti dalla Sed. Secondo i risultati, integrando queste fonti di dati complementari, il modello avrebbe raggiunto un’elevata accuratezza di classificazione.
«Il nostro algoritmo per la prima volta combina l’informazione morfologica proveniente dalle immagini degli oggetti con l’informazione sulla luce emessa dagli stessi in un largo spettro di lunghezze d’onda che vanno dall’ottico al vicino infrarosso, per ottenere una classificazione di oggetti astronomici in stelle, galassie e quasar (ossia oggetti quasi stellari associati a nuclei galattici attivi, compatti e luminosissimi)», spiega Nicola Rosario Napolitano, professore all’università Federico II di Napoli e coautore dello studio. «Se questa distinzione può sembrare banale per oggetti vicini, dove possiamo distinguere facilmente le stelle brillanti, quali oggetti compatti, da galassie estese, a disco con bracci di spirale o ellittiche, e dove spesso sono visibili sorgenti brillantissime in corrispondenza dei nuclei, questa distinzione diventa molto più confusa a mano a mano che le galassie si fanno lontane e la loro estensione e luminosità diventa confrontabile con quella di stelle poco brillanti della nostra galassia. La contaminazione reciproca di questi campioni diventa drammatica quando si vuole studiare le proprietà statistiche di oggetti lontani, come galassie o quasar ad alto redshift, che ci possono raccontare la storia delle prime fasi evolutive di questi oggetti».
Questo nuovo metodo di classificazione, riassumendo, si definisce un ibrido morfo-fotometrico, cioè utilizza simultaneamente le immagini (forma, struttura degli oggetti) e i colori multibanda, cosa che i metodi precedenti non facevano. L’algoritmo è stato addestrato utilizzando sorgenti confermate spettroscopicamente dalla data release 17 della Sdss, ed è stato poi applicato alla quinta release di dati Kids, nella quale ha classificato con successo oltre 27 milioni di sorgenti celesti più luminose della magnitudine 23 in banda r (una delle bande dello spettro visibile) su circa 1.350 gradi quadrati di cielo.
Così come l’abbiamo raccontato finora, il processo sembrerebbe lineare: c’è un’idea innovativa riguardante un processo di analisi dei dati, si sviluppa un modello, si testa sui dati e lo si affina fino a raggiungere delle performance che valgano una pubblicazione, e soprattutto che migliorino i metodi precedenti. La verità, però, è che questo lavoro e questo articolo hanno avuto una gestazione molto lunga, che ha a che fare poco con lo sviluppo dell’algoritmo in sé e molto più con il modo in cui funziona il mondo della ricerca.
«Questo è un articolo che ha avuto una lunga gestazione ed è cominciato quando io ero ancora professore ordinario presso la Sun Yat-sen University (Sysu), School of Physics and Astronomy», racconta Napolitano. «Lì, nei cinque anni di permanenza dalla fine del 2018 alla fine del 2023, avevo costruito un gruppo che si occupava di metodi di intelligenza artificiale applicati all’astrofisica, con particolare attenzione al trattamento di dati da grandi survey astronomiche in preparazione dei programmi che hanno preso avvio con Euclid e ora con Vera Rubin».
Il gruppo di studenti e alumni della Sysu messo in piedi da Napolitano, di cui faceva parte anche Rui Li, anche lui coautore dello studio e poi diventato professore associato alla Zhengzhou University, ha cominciato ad attrarre altri collaboratori che si sono avvicinati al nostro gruppo e nel tempo, racconta il ricercatore, è diventato tra i gruppi più all’avanguardia in Cina per queste tecniche. Tra questi, anche Hai-Cheng Feng dell’Accademia delle scienze cinese, primo autore di questo articolo, che era interessato a rifinire al massimo dell’accuratezza possibile, la separazione tra stelle, galassie e quasar/Agn. Non solo: Napolitano riuscì anche a portare i dati della survey Kids in Cina, aprendo la collaborazione ai colleghi cinesi. Dati che, come abbiamo visto, si sono rivelati fondamentali per testare il nuovo metodo.
«Le reti neurali da noi sviluppate, addestrate su oggetti di cui si conosceva una classificazione accurata basata si dati spettroscopici e di cui possedevamo immagini di alta qualità e magnitudini in 9 bande dalla Kilo Degree Survey (Kids), hanno permesso di raggiungere accuratezze impensabili, maggiori del 98 per cento», spiega infatti Napolitano. «Con queste reti, siamo riusciti ad ottenere, grazie all’altissima efficacia computazionale di queste reti, la classificazione di una campione di 27 milioni di oggetti di Kids in poche ore, fornendo per ogni oggetto sia la classe sia la probabilità di appartenere a questa classe».
L’algoritmo è stato poi applicato a 3,4 milioni di sorgenti Gaia con moto proprio o parallasse significativi – caratteristiche tipicamente esclusive delle stelle – ed è riuscito a identificare correttamente il 99,7 per cento degli oggetti come di origine stellare. Risultati altrettanto validi sono stati osservati con la Galaxy and Mass Assembly (Gama) Data Release 4, dove il 99,7 per cento delle sorgenti è stato classificato accuratamente come galassie o quasar.
Non solo, la ricerca ha scoperto che il modello potrebbe correggere le classificazioni errate nei cataloghi esistenti. Controlli casuali hanno mostrato che alcuni oggetti visivamente identificabili come galassie, ma erroneamente etichettati come stelle nella Sdss, sono stati correttamente riclassificati dalla rete neurale.
«Non abbiamo fatto una stima accurata della frazione di oggetti “corretti” dall’algoritmo nell’articolo perché questo era oltre gli scopi del lavoro, ma ci siamo sorpresi di trovare tanti oggetti con una classificazione errata», dice Napolitano. «Nell’articolo ne mostriamo una quarantina chiaramente errati in Sdss trovati tra quelli per cui noi avevamo una classificazione discrepante con la nostra. Il che ci porta a concludere che la classificazione del nostro algoritmo basato su AI è spesso più accurata di quella fatta con metodi classici».
Farebbe meglio dei metodi pre-esistenti, dunque, e sarebbe anche più veloce. Il nuovo algoritmo ha infatti classificato i 27 milioni di galassie di Kids in 12 ore circa, un lavoro che avrebbe richiesto diverse settimane/uomo con i tool semi-automatici, mesi/uomo se a questo metodo si fosse aggiunta una ispezione visuale di verifica.
«Il fatto di avere cresciuto una nuova categoria di astronomi con forti basi di machine learning, e viceversa esperti di machine learning che hanno imparato a maneggiare i dati, ha permesso al nostro gruppo di produrre strumenti che sono science-ready e che sono già applicati estensivamente a survey a grande campo da terra», conclude Napolitano. «Tra questi c’è l’analisi dei profili di brillanza superficiale delle galassie e la ricerca di lenti gravitazionali. Per questo, siamo già pronti alle sfide che il telescopio Vera Rubin con la sua survey Lsst ci sta per lanciare».
Per saperne di più:
- Leggi su The Astrophysical Journal Supplement Series l’articolo “Morpho-photometric Classification of KiDS DR5 Sources Based on Neural Networks: A Comprehensive Star–Quasar–Galaxy Catalog“, di Hai-Cheng Feng, Rui Li, Nicola R. Napolitano, Sha-Sha Li, J. M. Bai, Yue Dong, Ran Li, H. T. Liu, Kai-Xing Lu, Zhi-Wei Pan, Mario Radovich, Huan-Yuan Shan, Jian-Guo Wang, Wen-Zhe Xi, Ling-Hua Xie, Zun-Li Yuan e Yang-Wei Zhang