






Crediti: Esa/Ecf (lampo gamma); Markus Spiske/Pexels (codice)
“Qui è dove classifichiamo in modo inequivocabile tutti i Grb utilizzando un algoritmo di apprendimento automatico… fornendo un catalogo che separa tutti i Grb di Swift in due gruppi». È così, con l’invidiabile baldanza che solo un team guidato da tre studenti del primo anno di fisica può permettersi, che attacca un articolo pubblicato mercoledì scorso su The Astrophysical Journal Letters. Tutti i Grb. E in modo inequivocabile.
Christian Kragh Jespersen, Johann Bock Severin e Jonas Vinther – questi i nomi dei tre studenti del Niels Bohr Institute dell’università di Copenhagen che, sotto la guida di Charles Steinhard, hanno compiuto l’impresa – hanno tutte le ragioni per annunciare il loro risultato con un pizzico di trionfalismo. E qualche astrofisico che magari guarda con un po’ di sufficienza all’avanzare delle tecniche di intelligenza artificiale – della quale il machine learning costituisce un sottoinsieme – ha forse qualche motivo per iniziare a preoccuparsi. La classificazione dei Grb – i lampi di raggi gamma, i fenomeni più violenti ed energetici dell’universo dai tempi del Big Bang, scoperti per caso sul finire degli anni Sessanta – è una sfida che impegna gli astrofisici da decenni. Ne esistono infatti di due tipi: quelli “lunghi” (i long Grb) e quelli “corti” (gli short Grb). Dove l’esser “lungo” o “corto” dipende grosso modo dalla durata del lampo, con la soglia attorno a uno o due secondi. Grosso modo, attorno… il confine non è netto: c’è un’ampia zona grigia. Ed è un problema, perché i processi all’origine dei lampi gamma si distinguono invece in modo nettissimo, senza margine di sovrapposizione: stando ai modelli più accreditati, a produrre lampi gamma può essere sia il collasso di una stella massiccia sia la fusione di due stelle di neutroni, come quelle che hanno generato l’onda gravitazionale Gw 170817. I primi si presentano di solito come Grb lunghi, i secondi come Grb corti. Ma quelli nella zona grigia, a quale processo fisico vanno ascritti? E se i processi all’origine fossero più di due? O, invece, uno soltanto?
C’è poi un secondo problema. Oggi, per stabilire se un lampo di raggio gamma è lungo o corto, è determinante rilevarne il cosiddetto afterglow – l’emissione residua che può essere osservata per un periodo più o meno lungo dopo l’esplosione iniziale. Emissione che, a seguito di un sistema di alert su scala mondiale, i telescopi ottici e radio da terra e X dallo spazio cercano di catturare ogni qual volta un “cacciatore di Grb” – qual è appunto il telescopio spaziale Swift della Nasa – coglie un bagliore di luce gamma nel cielo. Finora, però, ricordano gli autori dello studio, solo l’un per cento delle volte è stato possibile cogliere l’afterglow e classificare il corrispondente lampo gamma.
L’algoritmo di machine learning del Niels Bohr Institute, invece, non risente di questi limiti. Non ha bisogno di alcun afterglow: per emettere la sua sentenza gli è sufficiente il cosiddetto prompt, la curva di luce iniziale del lampo gamma acquisita da Swift. E il risultato – lo potete vedere nel grafico al centro riportato qui sotto – mostra una suddivisione inequivocabile in due popolazioni. Non tre, non una: proprio due. Nettamente distinte. Un risultato niente affatto scontato.
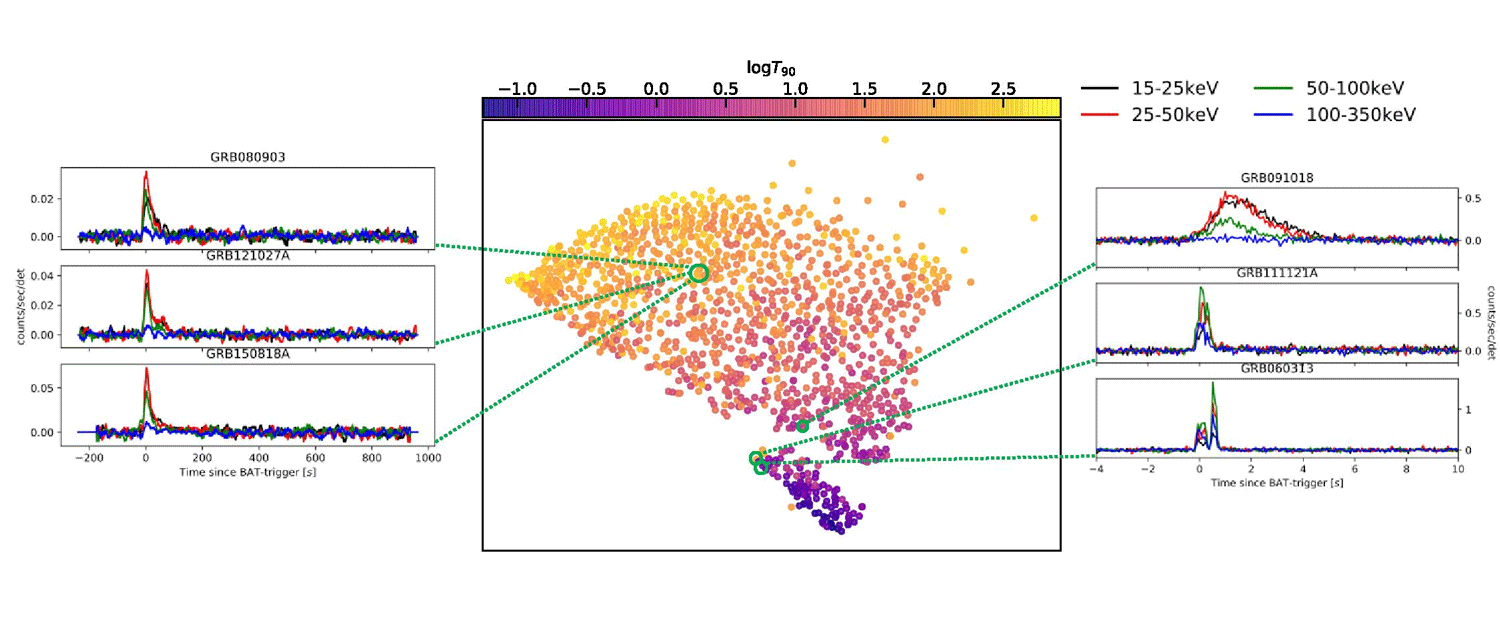
La figura al centro indica quanto siano o meno simili tra loro i Grb del campione. I punti più vicini sono più simili, e quelli più lontani lo sono meno. Si vede chiaramente che i punti si distribuiscono in due gruppi distinti, uno perlopiù arancione (il grande insieme in alto) e l’altro perlopiù blu (il piccolo insieme in basso, isolato dal resto). La colorazione è indicativa della durata. I punti tendenti all’arancione (dunque i Grb più lunghi) della prima popolazione potrebbero essere prodotti dal collasso di stelle massicce giunte al termine della loro evoluzione, mentre i punti tendendti al blu (i Grb più corti) della popolazione in basso sono quelli che si pensa possano essere prodotti dalla fusione di stelle di neutroni. Crediti: Jespersen et al., ApJL 2020
Com’è possibile? Invece di accontentarsi di un insieme limitato di statistiche, come è stato fatto fino a ora, gli studenti danesi hanno codificato tutte le informazioni disponibili su tutti i Grb di Swift avvalendosi, appunto, d’un algoritmo di apprendimento automatico di riduzione della dimensionalità detto t-Sne (t-distributed stochastic neighbor embedding). Semplificando un po’, si tratta di un algoritmo in grado, a partire da un insieme di dati complessi, di costruire una sorta di “mappa di somiglianza”, distribuendo su uno spazio a due dimensioni gli individui che formano il campione in base a quanto si assomigliano o meno fra loro: più sono “simili” – qualunque cosa questo significhi – più saranno vicini. E lo fa avvalendosi di quello che gli autori dello studio chiamano perplexity: una “perplessità” definita formalmente, un iperparametro che può essere approssimativamente interpretato come il numero tipico di “vicini” che dovrebbero essere considerati “simili” quando si calcolano le “distanze” di un individuo dagli altri – tutto fra virgolette, in quanto vicini e lontani qui non si riferisce a distanze in km o durate in secondi, ma al più impalpabile concetto, appunto, di similarità.
«La caratteristica unica di questo approccio”, osserva Jespersen, «è che t-Sne non forza la suddivisione in due gruppi. Lascia che i dati parlino da soli, e che siano loro a dirti come devono essere classificati». Detto altrimenti, nessuno ha suggerito all’algoritmo che possa aver senso distinguere i lampi gamma in long e short: è emerso dai dati.
Jespersen e i suoi compagni d’università hanno sperimentato l’algoritmo di apprendimento automatico t-Sne nell’ambito d’un progetto del primo anno del corso di laurea in fisica. «Alla fine del corso è apparso evidente che ci trovavamo davanti a un risultato assai significativo», dice il professor Steinhardt, il loro supervisore, sottolineando come la separazione netta in due gruppi di tutti i Grb osservati d Swift comprenda anche lampi gamma che in precedenza erano risultati molto difficili da classificare. «Questo è essenzialmente il passaggio zero nella comprensione dei lampi gamma. Per la prima volta, possiamo confermare che Grb brevi e Grb lunghi sono effettivamente fenomeni completamente distinti».
Per saperne di più:
- Leggi su The Astrophysical Journal Letters l’articolo “An Unambiguous Separation of Gamma-Ray Bursts into Two Classes from Prompt Emission Alone”, di Christian K. Jespersen, Johann B. Severin, Charles L. Steinhardt, Jonas Vinther, Johan P. U. Fynbo, Jonatan Selsing e Darach Watson