





Oltre al Flagship 2 galaxy mock, il catalogo simulato di oltre tre miliardi di galassie creato dalla collaborazione Euclid a partire dalla Euclid Flagship Simulation e pubblicato lunedì scorso, esistono molti altri strumenti per supportare lo sfruttamento scientifico dei dati raccolti dalla missione dell’Agenzia spaziale europea che indaga sul “lato oscuro” del cosmo. Ne sono un esempio i cataloghi di galassie e aloni di materia oscura basati su migliaia di simulazioni cosmologiche sviluppate in Italia per esplorare in dettaglio la distribuzione tridimensionale delle galassie nell’universo.
Per saperne di più, Media Inaf ha intervistato Pierluigi Monaco, professore di astrofisica e cosmologia all’Università di Trieste, esperto di simulazioni numeriche e tra i coordinatori del Galaxy Clustering Science Working Group all’interno dello Euclid Consortium. Monaco è primo autore di un articolo, appena accettato dalla rivista Astronomy & Astrophysics, che presenta un totale di ben 4500 simulazioni, ciascuna contenente miliardi di galassie del tutto analoghe a quelle di cui il satellite Euclid sta realizzando non solo le immagini ma anche gli spettri.
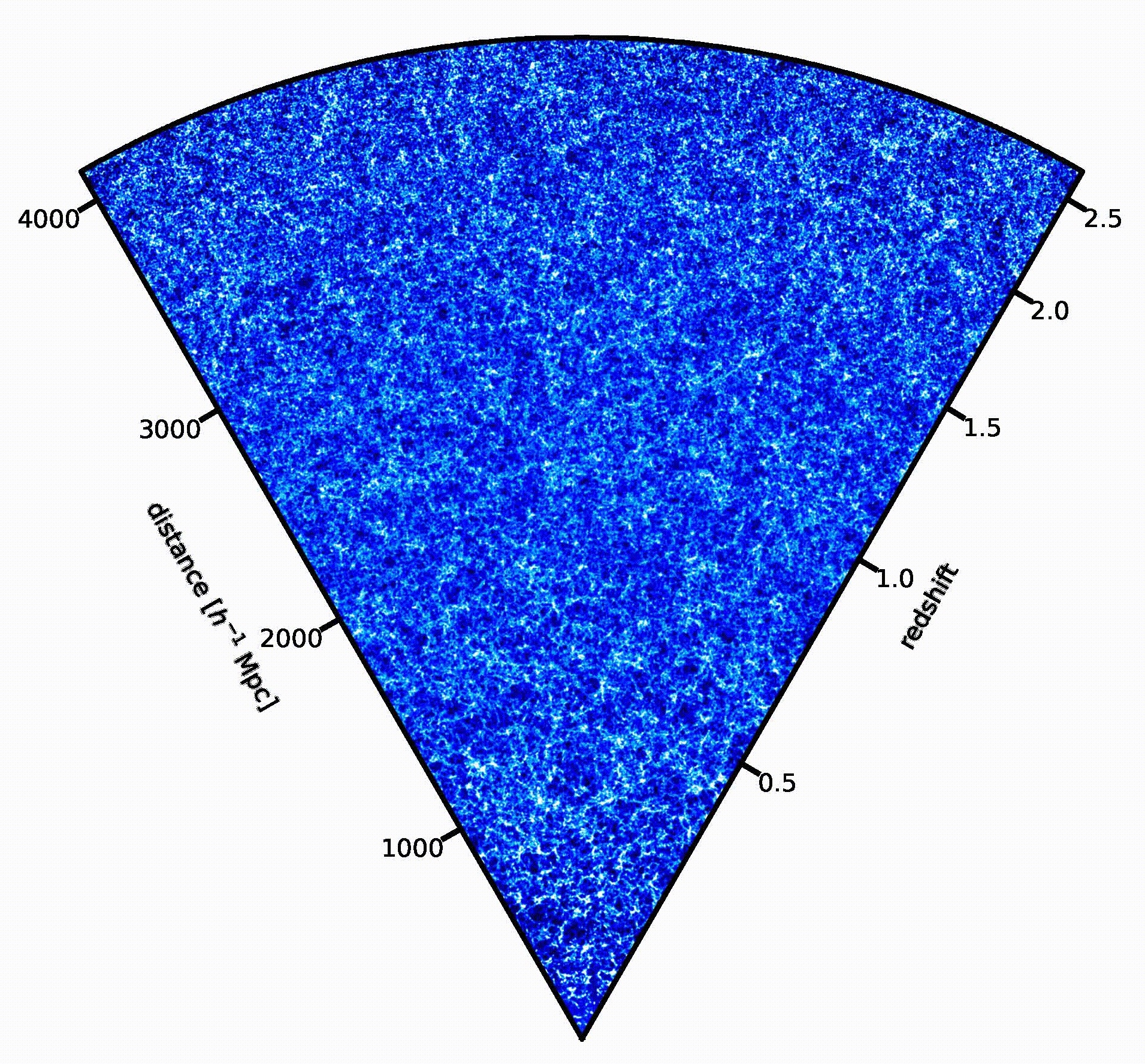
Visualizzazione di una delle simulazioni del cielo di Euclid realizzate con il codice Pinocchio. Le regioni più chiare rappresentano porzioni più dense della rete cosmica. L’osservatore si trova nell’angolo in basso. Crediti: P. Monaco
Professor Monaco, perché avete sviluppato queste nuove simulazioni?
«Queste simulazioni sono state costruite per lo spectroscopic galaxy clustering, vuol dire lo studio della distribuzione nello spazio delle galassie di cui abbiamo lo spettro e, quindi, conosciamo la distanza. È diverso dal photometric galaxy clustering, che è la stessa operazione però fatta su galassie di cui non abbiamo lo spettro, ma abbiamo solo una stima della distanza attraverso il cosiddetto redshift fotometrico, che è molto più impreciso. Le simulazioni sono già in uso per per l’analisi dei dati all’interno della collaborazione Euclid. Con l’uscita dell’articolo, vengono messe a disposizione della comunità per chiunque voglia utilizzarle, anche per altri scopi».
Ma con tutti i dati raccolti da Euclid, che ci sveleranno com’è fatto l’universo, sono ancora necessarie le simulazioni?
«Abbiamo un modello molto potente che ci fa capire come funziona l’universo, a costo di riempirlo di sostanze invisibili, la materia oscura e l’energia oscura. Così stiamo investendo miliardi di euro per mappare il cielo fino a distanze molto grandi, perché se tracciamo la storia di espansione e l’evoluzione delle perturbazioni in grande dettaglio, possiamo riuscire a capire di che cosa è fatto veramente l’universo. Però non basta una misura. Quando si fa una misura, la parte difficile è la barra d’errore. Per capire la barra d’errore delle nostre misure, dato che è difficile predire come evolve un sistema autogravitante (come le galassie e gli aloni che le ospitano, ndr), dobbiamo fare delle simulazioni e siccome vogliamo capire l’errore ne dobbiamo fare tante. Non esiste un metodo analitico per predire con carta e penna come evolvono le perturbazioni. Ovvero, esistono dei metodi, ma hanno dei limiti. Il modo più pulito è far girare le simulazioni».
E perché serve realizzare delle simulazioni appositamente per Euclid?
«Per estrarre informazioni sulla cosmologia da un campione di galassie, dobbiamo controllare tutti i possibili errori sistematici. Siccome l’evoluzione delle galassie e della struttura a grande scala è non lineare, il modo più pulito di fare predizioni sulla distribuzione di galassie è attraverso le simulazioni numeriche. Una survey come Euclid campiona un volume molto grande di cielo, e campiona galassie che vivono in aloni di materia oscura relativamente piccoli. Parliamo di centinaia di miliardi di masse solari, dunque un po’ più piccoli di quello che ospita la Via Lattea, che è dieci volte più grande, mille miliardi di masse solari. Per avere una simulazione che campiona un volume molto grande e trova aloni molto piccoli, c’è bisogno di tantissime particelle. Migliaia di miliardi di particelle. Fare una simulazione di questo tipo è uno sforzo enorme».

Pierluigi Monaco, professore all’Università di Trieste
Una di queste simulazioni è la Euclid Flagship Simulation, così importante da essere soprannominata “ammiraglia” (dall’inglese, flagship) di tutte le simulazioni a supporto di Euclid, pubblicata per la prima volta nel 2017 e, nella sua seconda versione, nel 2020.
«Sì, però la Flagship è semplicemente una realizzazione di come può essere l’universo in un certo volume, fatta su una specifica cosmologia. Se vogliamo controllare gli errori di misura dei parametri cosmologici che troviamo attraverso queste simulazioni, anzi che troviamo nel nostro universo di cui ipotizziamo la simulazione di una rappresentazione specifica, non abbiamo bisogno di una simulazione: abbiamo bisogno di migliaia di simulazioni. Fare migliaia di simulazioni come la Flagship è fuori discussione. Quello che però si può fare è utilizzare un “codice veloce” che riesce a fare una simulazione senza andare a integrare la traiettoria di ogni singola particella, ma dando soltanto un’approssimazione di quello che è il risultato».
Lei ha sviluppato uno di questi codici veloci per le simulazioni cosmologiche…
«Ci sono vari codici in giro che fanno questa operazione. Quello che ho sviluppato io già a partire dal millennio scorso, perché il lavoro è partito alla fine degli anni Novanta, si chiama Pinocchio. È un acronimo che sta per PINpointing Orbit-Crossing Collapsed HIerarchical Objects. Vuol dire che trova la posizione degli aloni in un volume cosmologico. Con quattro milioni di ore di calcolo sono riuscito a creare un set di cataloghi simulati mille volte più grande di quello della Flagship, che invece ha richiesto qualcosa come 40 milioni di ore».
Aspetti un attimo, quattro milioni di ore sono equivalenti a oltre cento anni, e 40 milioni di ore oltre mille anni. Che significa tutto questo?
«Le mie simulazioni girano sui supercomputer: per le più grandi ho utilizzato 24 nodi, ognuno con 48 unità di calcolo (core). Tutte le unità di calcolo si dividono il lavoro, in questo modo un’ora di orologio corrisponde a 1152 ore di calcolo di un singolo core. E così quattro milioni di ore corrispondono ad alcuni mesi di lavoro».
Quindi queste simulazioni non possono girare su un semplice laptop in ufficio. Di che tipo di macchine hanno bisogno?
«Le mille simulazioni più grandi sono state realizzate sulla macchina Galileo 100 del Cineca, con tempo di calcolo fornito dal Cineca e anche grazie all’Istituto nazionale di fisica nucleare. Poi c’è anche un altro set di 3500 simulazioni, che sono un po’ più piccole ma sono tante, perché quando la box è un po’ più piccolina uno può permettersi di far girare più simulazioni: queste sono state realizzate nella macchina Pleiadi, una facility nazionale dell’Inaf, l’Istituto nazionale di astrofisica a Trieste. Stiamo già lavorando sulla versione successiva del codice che sta girando sul supercomputer Leonardo al Tecnopolo di Bologna, grazie al Centro Nazionale di Ricerca in High Performance Computing, Big Data e Quantum Computing – Spoke 3».
A questo punto, immagino che non si possano nemmeno salvare i dati delle simulazioni sul proprio computer personale… come si fa?
«Ho dovuto chiedere 300 terabyte agli archivi Inaf per tenere queste simulazioni! Gestire un grandissimo numero di realizzazioni è la cosa più difficile quando si lavora con le simulazioni: tutto è molto grande, tutto diventa lento. Ogni operazione anche banale richiede un tempo piuttosto lungo. Bisogna trovare qualcuno disponibile a ospitare queste centinaia di terabyte, che sia disponibile a prendersi in carico tutta questa mole di dati e poi condividerla. Perché rendere le simulazioni disponibili al pubblico significa rendere le simulazioni accessibili a un generico utente. Questo non è banale, c’è bisogno di infrastrutture».
Parlavamo di velocità… come fa Pinocchio a essere più veloce delle simulazioni tradizionali?
«Perché parte dalle stesse condizioni iniziali di una simulazione, però invece di far girare la simulazione, cioè trovare le traiettorie di ogni singola particella a partire dalle condizioni iniziali, cerca di capire quali particelle andranno a finire negli aloni di materia oscura. Quindi direttamente, senza fare la simulazione, trovo il risultato finale, ovvero la posizione degli aloni e la loro massa. Questo ovviamente è solo una piccola parte dell’informazione che si estrae da una vera simulazione cosmologica, però è quella cruciale per creare un catalogo di galassie, perché poi alla fine quello che serve è una mappa degli aloni di materia oscura e delle galassie che questi contengono».
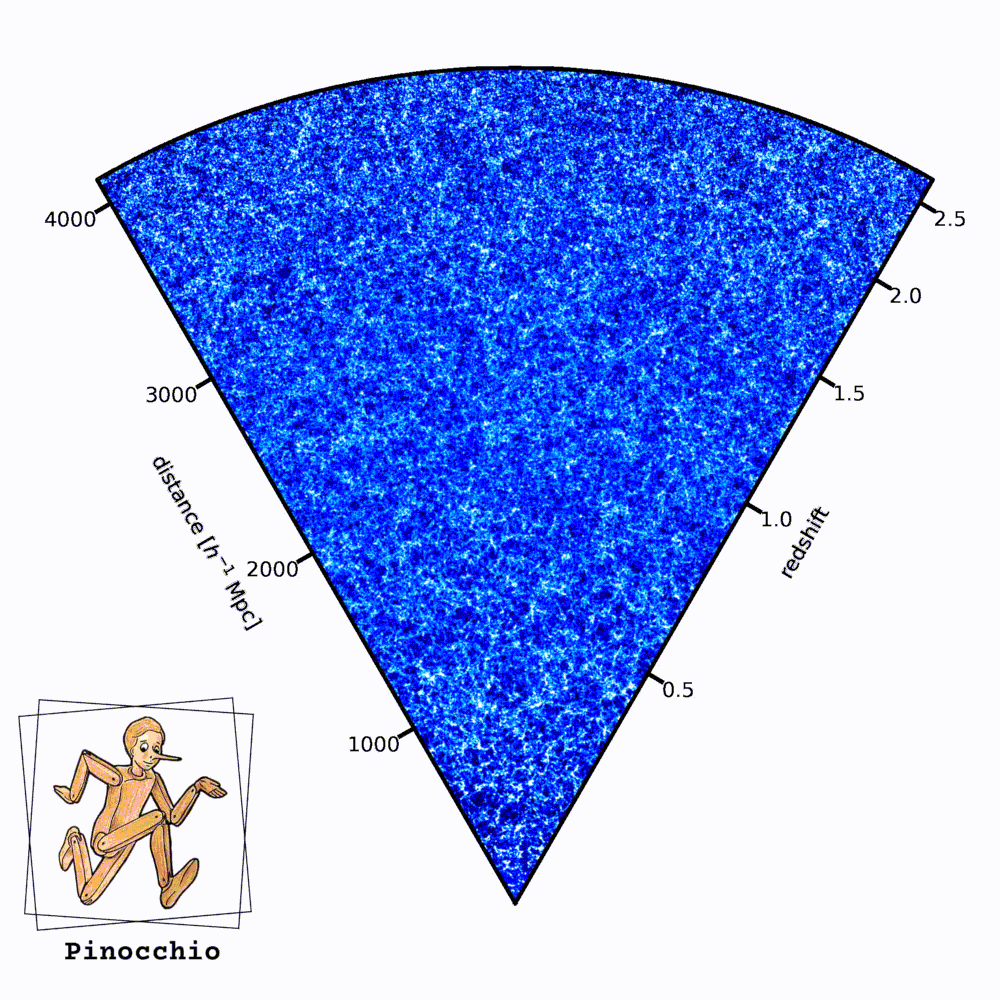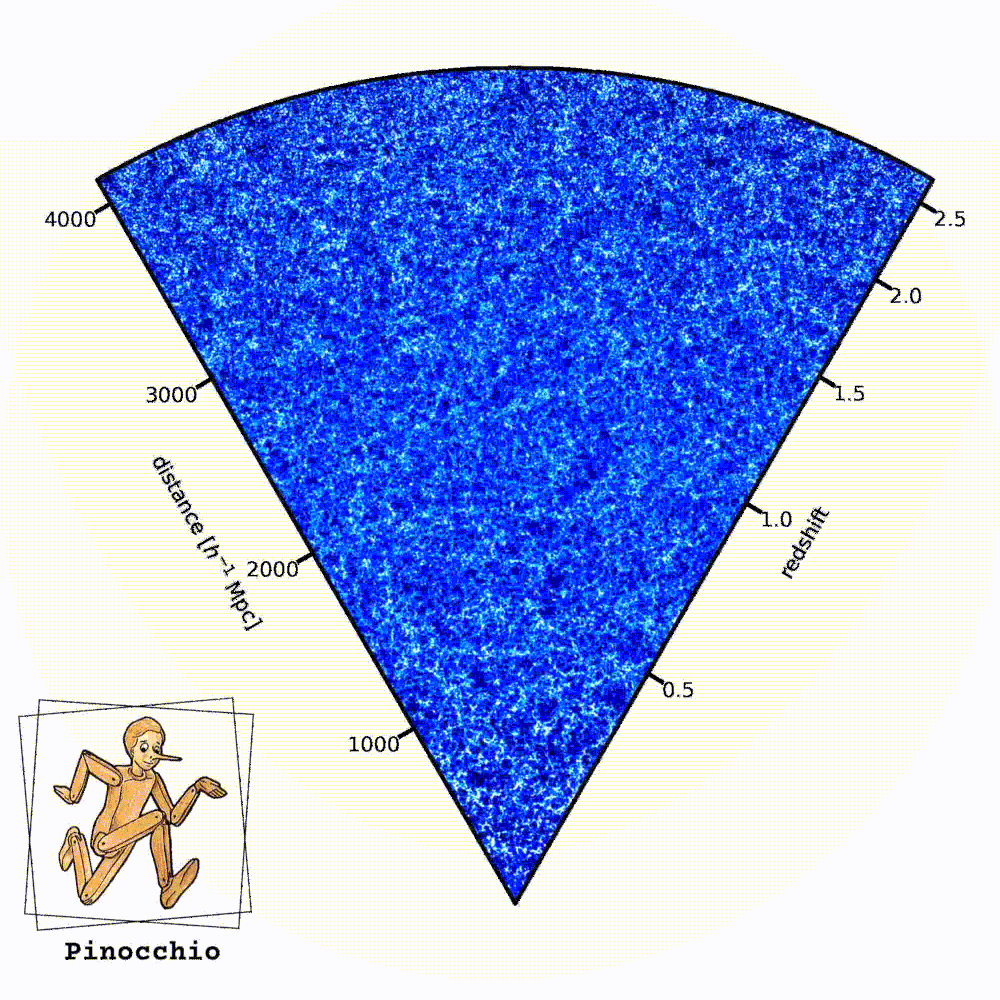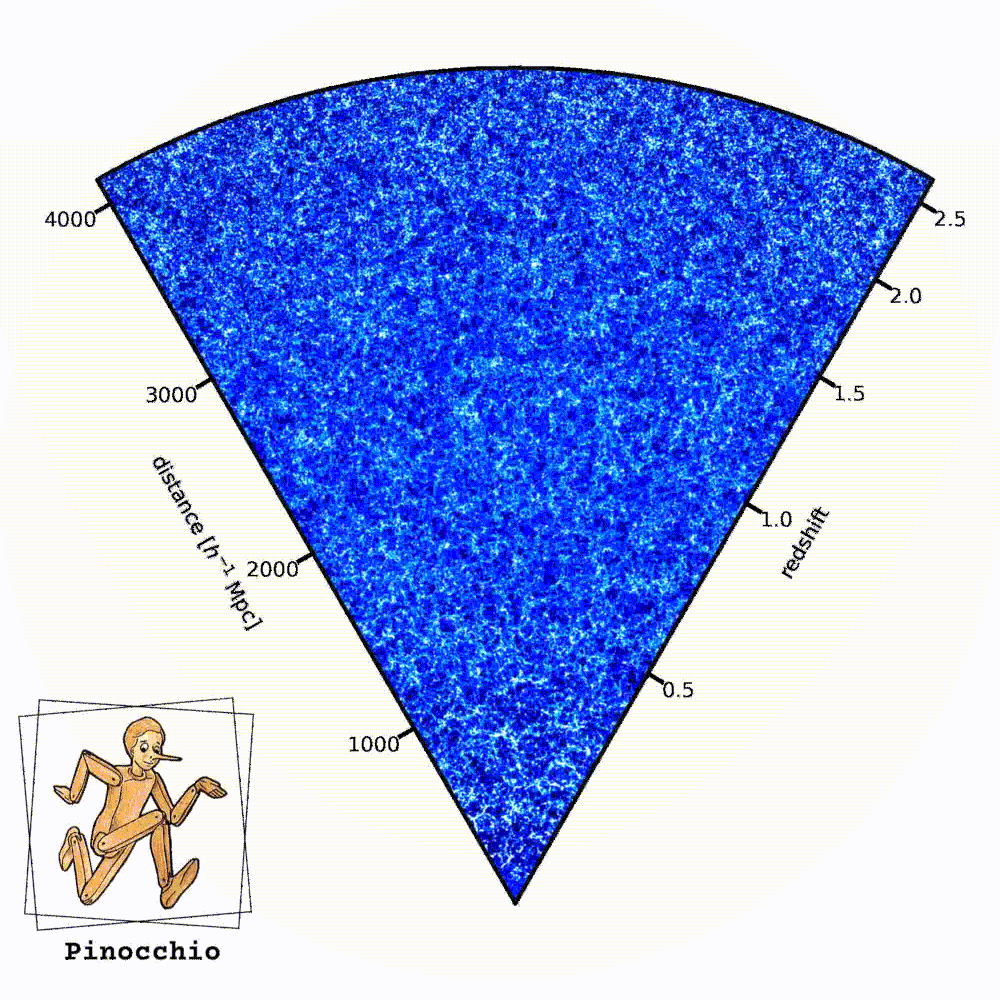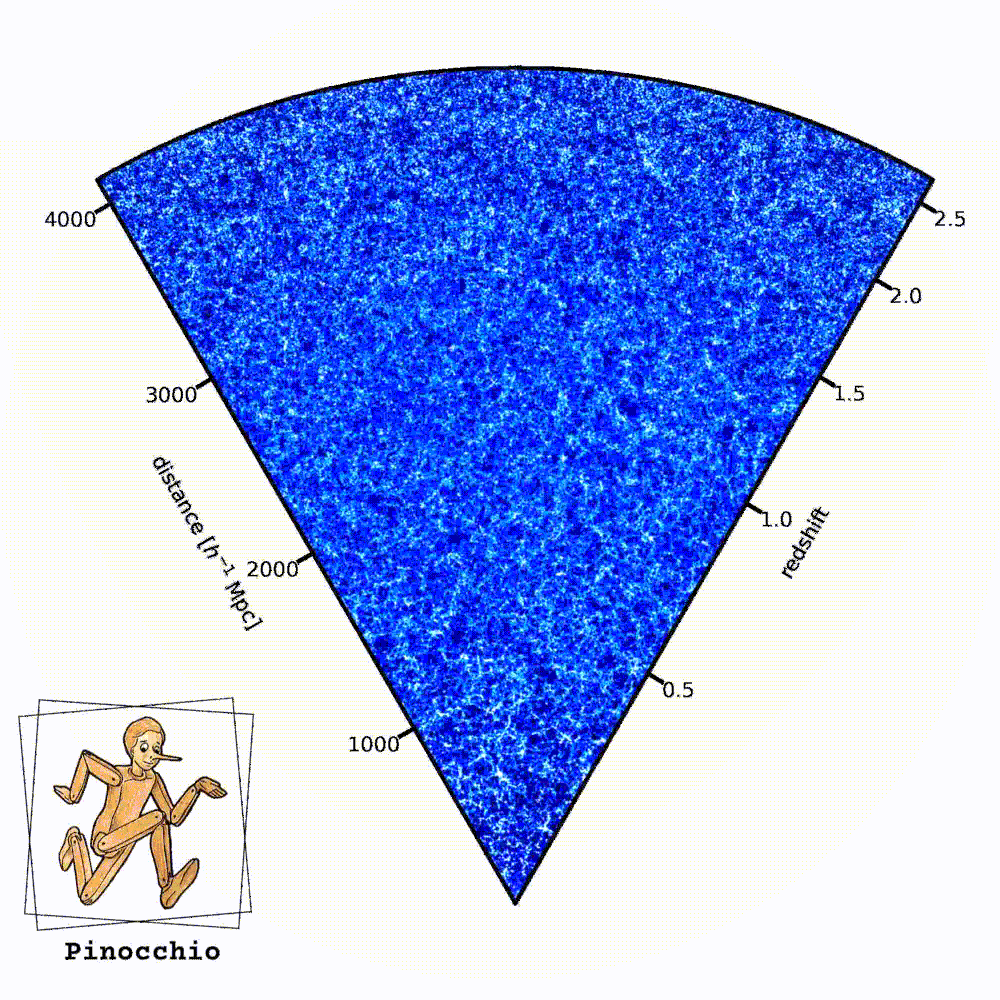
Cento realizzazioni diverse dell’universo di Euclid realizzate con il codice Pinocchio. Le regioni più chiare rappresentano porzioni più dense della rete cosmica. L’osservatore si trova nell’angolo in basso. Crediti: P. Monaco; logo: M. Monaco
Facciamo un passo indietro: che cos’è un alone di materia oscura?
«Alcune simulazioni contengono un trattamento delle particelle che noi chiamiamo in gergo barioni, cioè le particelle di materia ordinaria, che sono soggette a processi astrofisici, quindi si riscaldano, si raffreddano, formano stelle, buchi neri, eccetera. Queste simulazioni idrodinamiche della formazione di galassie sono molto costose: il volume più grande che si riesce a utilizzare è di qualche centinaia di milioni di anni luce al cubo, mentre per Euclid abbiamo bisogno di volumi pari a una decina di miliardi di anni luce al cubo. Simulazioni così grandi non possono trattare altro che la gravità, perché oggi è impossibile pensare, anche con i computer più potenti, di risolvere la formazione delle galassie. Quello che si fa di solito è seguire l’evoluzione della materia e, poiché la maggior parte della materia è materia oscura, si tratta tutta la materia come se fosse materia oscura, quindi soggetta solo alla gravità. A questo punto, quello che succede è che la materia oscura si condensa in strutture gravitazionalmente legate, che si chiamano aloni e che hanno una densità particolarmente alta. Sono della specie di grumi che si formano nell’evoluzione naturale della materia oscura. Questi aloni contengono le galassie, quindi quello che si fa con le simulazioni grandi come la Flagship è raccogliere questi aloni e poi popolarli con delle galassie. Per formare le stelle c’è bisogno di una densità di gas molto alta e il posto dove troviamo questa densità sono gli aloni di materia oscura».
Cosa succede con Pinocchio, invece?
«Una simulazione tradizionale integra l’orbita di ogni particella calcolando la forza rispetto a tutte le altre particelle, con tutta una serie di tecniche per rendere il calcolo più efficiente possibile, però con l’ipotesi di calcolare la traiettoria con una certa accuratezza. La maggior parte del tempo di una simulazione N-body viene speso integrando le traiettorie dentro gli aloni. Quello che fa un codice come Pinocchio, invece, è predire l’istante in cui una particella, che inizialmente si evolve nello spazio intergalattico, passa a una dinamica diversa, tuffandosi nelle zone in cui si trovano gli aloni di materia oscura, dove le particelle si mischiano. Quindi già nelle condizioni iniziali, l’algoritmo identifica tutte le particelle che poi entreranno in un alone di materia oscura. A questo punto utilizza una tecnica chiamata Lagrangian perturbation theory per predire dove sarà l’alone a un certo istante».
In un certo senso, il codice “imbroglia”. È per questo che si chiama Pinocchio?
«Quando ho pubblicato il codice per la prima volta, ho cercato a lungo un acronimo finché non ho avuto una fulminazione: potevo costruire un acronimo basato sulla parola Pinocchio. A quel punto è diventato Pinocchio, chiaramente un nome che si fa ricordare. Pinocchio è un un personaggio fantastico in tutti i sensi, racconta la crescita di un bambino vivace e poco incline a seguire le regole. Ed è famoso per dire le bugie. Per giustificare il fatto che stavo chiamando il codice come un famoso mentitore, ho detto che sì, lui mente perché fa finta di essere una simulazione N-body, però è molto più veloce: infatti il logo raffigura un burattino che corre».
Le visualizzazioni di queste simulazioni hanno un aspetto curioso, a forma di “cono”. Che cosa rappresenta?
«Di solito una simulazione prende una scatola cubica (un pezzo di universo a forma di cubo, ndr) e la fa evolvere nel tempo. L’output di una simulazione è lo stato di tutte le particelle a un certo istante, per tanti istanti di tempo. Quando noi però osserviamo l’universo, noi lo osserviamo in un modo un pochino particolare: siamo in un fissi in un punto e più guardiamo lontano, più andiamo indietro nel tempo. Quindi lo osserviamo nel cosiddetto “cono-luce passato”, che è un concetto della relatività speciale e si riferisce a un diagramma spaziotemporale. Mentre l’output logico di una simulazione è lo stato delle particelle a un certo istante, l’output più naturale per il modo con cui noi osserviamo l’universo è il cono-luce passato: vorrei avere la posizione delle particelle, o ancora meglio degli aloni di materia oscura, nell’istante in cui sono visibili. Un output che è a tempi diversi, a distanze diverse dall’osservatore. La cosa comoda di Pinocchio è che questa operazione, che di solito per le simulazioni richiede un’elaborazione molto pesante, viene fatta dal codice stesso, quindi l’output del codice è direttamente un catalogo di aloni di materia oscura nel cono-luce passato. All’istante giusto in cui noi lo possiamo osservare. Questa caratteristica rende questo campione di simulazioni che abbiamo prodotto unico, perché è la più grande collezione di simulazioni di aloni nel cono-luce passato che sia mai stata prodotta».
Cosa cambia tra una simulazione e l’altra?
«Cambia solo il seme di generazione dei numeri random. Quando creiamo le condizioni iniziali di una simulazione, c’è una parte di aleatorietà legata al fatto che le condizioni iniziali sono un campo random. Se generi tante realizzazioni cambiando solo il seme del numero random, generi tanti universi equivalenti che hanno la stessa cosmologia e sono soggetti alla stessa fisica, però la parte che è impossibile prevedere, che è la aleatorietà del processo di formazione delle fluttuazioni, è riprodotta in maniera libera».
E i parametri cosmologici?
«Sono tutti identici. Cambia il nome delle simulazioni, ovviamente, altrimenti faremmo confusione, e il seme dei numeri random. Il resto è tutto identico».
Allora come si fa a indagare il modello cosmologico?
«Ci sono due approcci che in questo momento vanno per la maggiore per estrarre i parametri cosmologici dalle survey di galassie. Nell’approccio classico, io prendo le mie galassie, ne costruisco una funzione di correlazione a due punti – che è una statistica che mi dice in che modo sono distribuite le galassie – poi ho dei modelli che predicono questa funzione e che dipendono dai parametri cosmologici. Posso utilizzare dei metodi statistici per trovare il modello che riproduce meglio i dati. Per far questo però ho bisogno di conoscere l’incertezza sui dati, che posso costruire dalle simulazioni. Nell’approccio classico, questo si fa scegliendo una cosmologia specifica, cioè un set di parametri cosiddetti di fiducia, però tenendo conto il fatto che la cosmologia vera che poi si trova alla fine dell’analisi potrà essere diversa. E così trovo i parametri cosmologici. Poi c’è un altro approccio, che è nuovo e sta diventando importante: la simulation-based inference, che utilizza le simulazioni direttamente per stimare i parametri cosmologici attraverso metodi di machine learning. Per far questo ho bisogno di un set di simulazioni fatto girare ognuna con una cosmologia diversa. Dal punto di vista delle simulazioni i due approcci sono molto simili, cioè devo fare circa le stesse simulazioni, solo che nell’approccio classico, che è quello che stiamo utilizzando attualmente, si fanno tutte le simulazioni con la stessa cosmologia. Nell’approccio nuovo, ogni simulazione ha la sua cosmologia diversa, in modo che la macchina impari qual è la cosmologia giusta, quella che meglio si adatta ai dati. Queste simulazioni sono state fatte per la data release 1 di Euclid (la cui pubblicazione è prevista per ottobre 2026, ndr). Credo che le simulazioni che faremo per la data release successiva saranno fatte invece in un’ottica un po’ diversa, andando nella direzione della simulation-based inference».
In cosa si differenziano invece i cataloghi simulati con Pinocchio e il Flagship 2 galaxy mock pubblicato qualche giorno fa?
«Quello è un lavoro molto più ampio. La Flagship è una simulazione di sola materia oscura con l’output nel cono di luce passato, quindi ancora una volta andando a vedere gli aloni al momento giusto in cui possono essere visti. Però gli aloni sono stati popolati da galassie che non vogliono riprodurre solo il campione spettroscopico, ma quasi tutto quello che può voler studiare con Euclid: galassie fotometriche, di cui si ha l’immagine ma non necessariamente lo spettro, ammassi di galassie, tutte le proprietà di evoluzione delle galassie, tutte le proprietà di clustering, il lensing gravitazionale. A ogni galassia sono associate più di 100 colonne, mentre nei miei cataloghi, a ogni galassia sono associate meno di 10 colonne. È un approccio molto diverso: a noi interessa fare un’operazione specifica molto importante, ma molto focalizzata. La Flagship invece vuole fare tutto ciò che Euclid può fare, o quasi tutto».
Per saperne di più:
- Leggi su Arxiv il preprint dell’articolo “Euclid preparation. Simulating thousands of Euclid spectroscopic skies” di Euclid Collaboration: P. Monaco, et al.
- Leggi su The Astrophysical Journal l’articolo “Predicting the Number, Spatial Distribution, and Merging History of Dark Matter Halos” di Pierluigi Monaco, Tom Theuns, Giuliano Taffoni, Fabio Governato, Tom Quinn, Joachim Stadel
- Leggi su Monthly Notices of the Royal Astronomical Society l’articolo “The pinocchio algorithm: pinpointing orbit-crossing collapsed hierarchical objects in a linear density field” di Pierluigi Monaco, Tom Theuns, Giuliano Taffoni